导语: 继今天(11月3日)下午多名用户反映DeepSeek 出现「无法打开」「服务器繁忙」后,相关话题在社交媒体和开发者社群 中持续发酵。截至发稿时,虽然部分用户的访问已在缓慢恢复,但此次事件也再次将AIGC(生成式AI)服务在高并发流量 下的“脆弱性”问题推至台前。
一、事件回顾
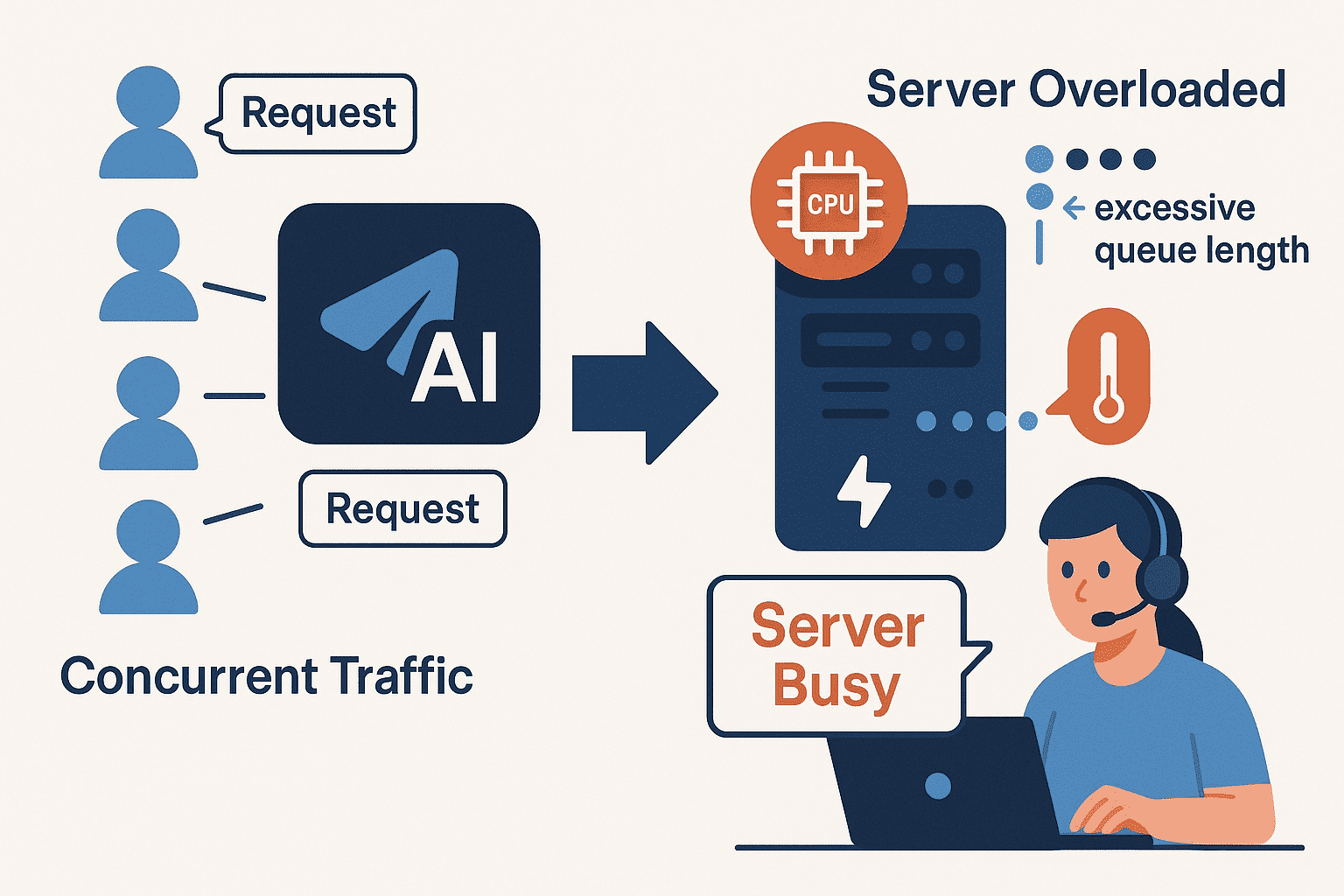
此次服务异常始于今天下午16:00左右,问题迅速扩大。DeepSeek旗下的AI助手App和网页版 均出现大面积访问困难,用户在提交问题后长时间无法收到响应,或直接收到“服务器繁忙 (server busy),请稍后重试”的提示。
与此同时,在多个技术论坛和开发者群组 中,大量依赖DeepSeek API开放平台 的企业用户集中反映,其API调用超时错误率激增 ,导致下游的自动化工具或应用服务陷入停顿。
二、官方或平台层级动向
截至发稿时,DeepSeek官方 尚未就此次大范围拥堵发布详细的技术说明。其官网的“服务状态”页面 也未及时更新故障信息。
不过,有技术用户在尝试访问时发现,平台似乎已启动临时的“速率限制” (Rate Limiting) 措施,例如显著延长了免费用户的响应等待时间,这被视为一种优先保障服务器不再发生“级联故障” (cascading failure) 的“优雅降级” (Graceful Degradation) 策略。
三、为何AI服务会“服务器繁忙”
此次拥堵并非个例,此前OpenAI的ChatGPT也曾多次发生全球性宕机 。专业分析指出,AI大模型服务之所以比传统网页更容易“繁忙”,背后有深刻的技术原因:
- 高昂的“推理”成本: 用户访问传统网页,服务器大多执行的是简单的数据库读取。但用户向AI助手每一次提问,都会触发大模型进行一次完整的“推理”(Inference)计算,这需要消耗巨量的GPU算力 ,其资源消耗远非传统Web服务可比。
- “瞬时”且“集中”的并发压力: AI助手的用户行为模式非常集中。例如在平台发布新模型(如DeepSeek近期发布的V3.1 和V3.2-Exp )后,大量“尝鲜”用户会涌入 ,并在短时间内提交长对话、代码编写 等高算力消耗的任务。这种瞬时洪峰极易突破服务器的CPU 和内存 阈值,导致服务过载。
- 复杂架构的更新风险: AI技术迭代极快。例如DeepSeek采用了先进的混合专家模型(MoE) 架构。在平台为这些复杂模型进行后端服务节点更新或数据切换时,系统容量或路由可能短暂下降,一旦此时遭遇流量高峰,就极易导致服务“雪崩”。
四、对用户的实际影响
此次服务中断的影响是双重的 。
- 对普通用户: 主要影响是任务无法提交、正在进行中的长对话(上下文)丢失。由于需要多次刷新重试,严重影响了工作和学习效率。
- 对企业和开发者: 影响则更为严重。许多依赖DeepSeek API 的内容创作者、程序员和企业,其自动化工作流(Workflow)被完全打断。基于API的客服机器人、内容生成工具等服务陷入瘫痪,可能造成直接的业务损失。
五、未来是否还会发生
业内人士普遍认为,只要是云端AI服务,大流量拥堵的风险 就将长期存在。OpenAI的CEO也曾在宕机后将其归咎于“流量远超预期” 。
未来此类事件是否会频繁发生,取决于平台方(如DeepSeek)在“弹性扩容”、“自动扩缩” 策略与高昂的算力成本之间的平衡。对于用户而言,短期内最好的办法是关注官方状态页 、社群公告,并在必要时准备替代方案 。
结语: 此次DeepSeek事件再次提醒所有AI平台,在追求模型能力快速增长的“创新竞赛”中 ,基础架构的“稳定性”和“可靠性” 建设需要同步跟上。毕竟,对于用户和开发者而言,一个“能用”且“稳定”的服务,才是其付费和依赖的基石。



